bulk_reshuffle #
描述 #
bulk_reshuffle 可以分析 Elasticsearch 的批次请求,并按照文档进行解析,可以根据需要将文档分门别类,归档存储在队列中,通过先落地存储,业务端请求可以快速返回,从而解耦前端写入和后端 Elasticsearch 集群。bulk_reshuffle 需要离线管道消费任务来配合使用。
通过 bulk_reshuffle 过滤器生成的队列,元数据会默认带上 "type": "bulk_reshuffle" 以及 Elasticsearch 的集群信息,如:"elasticsearch": "dev",通过网关查看队列的 API 也可以查看,如下:
curl http://localhost:2900/queue/stats
{
"queue": {
"disk": {
"async_bulk-cluster##dev": {
"depth": 0,
"metadata": {
"source": "dynamic",
"id": "c71f7pqi4h92kki4qrvg",
"name": "async_bulk-cluster##dev",
"label": {
"elasticsearch": "dev",
"level": "cluster",
"type": "bulk_reshuffle"
}
}
}
}
}
}
节点级别的异步提交 #
极限网关可以本地计算每个索引文档对应后端 Elasticsearch 集群的目标存放位置,从而能够精准的进行请求定位,在一批 bulk 请求中,可能存在多个后端节点的数据,bulk_reshuffle 过滤器用来将正常的 bulk 请求打散,按照目标节点或者分片进行拆分重新组装,避免 Elasticsearch 节点收到请求之后再次进行请求分发, 从而降低 Elasticsearch 集群间的流量和负载,也能避免单个节点成为热点瓶颈,确保各个数据节点的处理均衡,从而提升集群总体的索引吞吐能力。
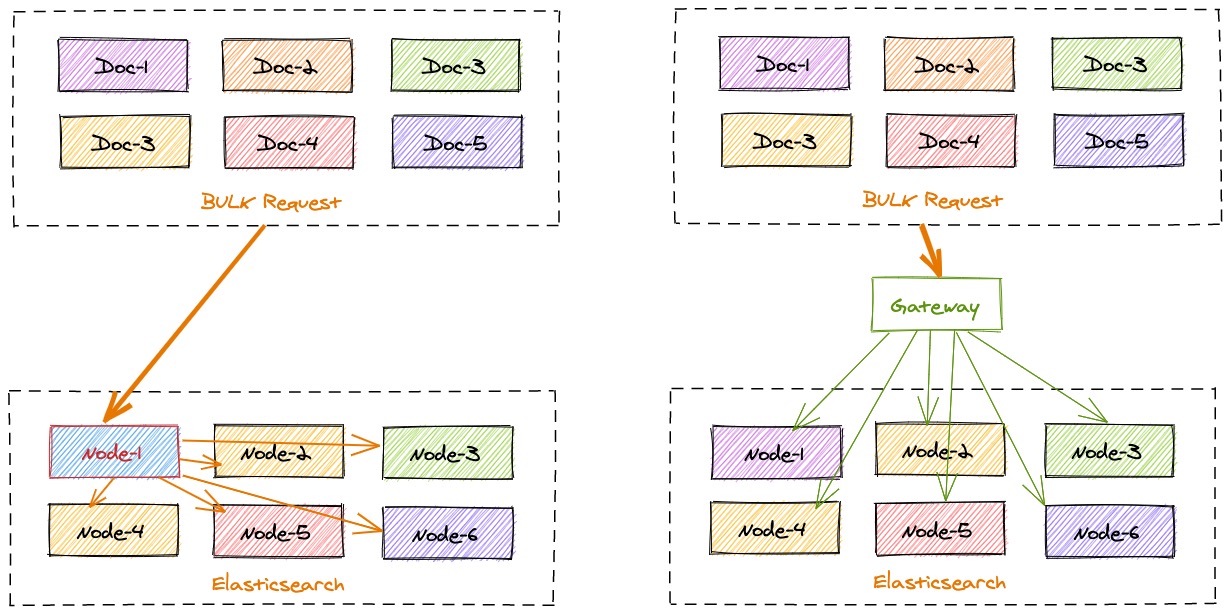
定义流程 #
一个简单的示例如下:
flow:
- name: online_indexing_merge
filter:
- bulk_reshuffle:
elasticsearch: prod
level: node #cluster,node,shard,partition
- elasticsearch:
elasticsearch: prod
refresh:
enabled: true
interval: 30s
以上配置表示会将 bulk 请求拆分,按照索引文档所对应的目标节点,重新拆组装,将数据先落地到本地磁盘队列,然后通过单独的任务来消费提交,分别提交到目标 Elasticsearch 节点。

使用该 filter 的好处是,即使后端 Elasticsearch 集群出现故障也不会影响索引操作的正常进行,因为请求都已经存放在网关本地的磁盘队列,从而解耦了前端索引和后端集群的依赖。因此就算后端 Elasticsearch 集群出现故障、进行重启、或是版本升级都不会影响正常的索引操作。
配置消费管道 #
网关将请求落地磁盘之后,需要配置一个消费队列的管道来进行数据的提交,如下:
pipeline:
- name: bulk_request_ingest
auto_start: true
processor:
- bulk_indexing:
bulk_size_in_mb: 10 #in MB
queues:
type: bulk_reshuffle
level: node
这里使用了一个名为 bulk_request_ingest 的管道任务,并且设置要订阅的目标的队列的过滤条件为:type: bulk_reshuffle 和 level: node,还可以设置 bulk 提交的批次大小。
这样当极限网关收到的节点级别的请求会自动的发送到对应的 Elasticsearch 节点。
分片级别的异步提交 #
分片级别的异步提交比较适合单个索引数据量很大,需要单独处理的场景,通过将索引拆分到分片为单位,然后让 bulk 请求以分片为单位进行提交,进一步提高后端 Elasticsearch 处理的效率。
具体的配置如下:
定义流程 #
flow:
- name: online_indexing_merge
filter:
- bulk_reshuffle:
elasticsearch: prod
level: shard
- elasticsearch:
elasticsearch: prod
refresh:
enabled: true
interval: 30s
将拆装的级别设置为分片类型。
定义管道 #
pipeline:
- name: bulk_request_ingest
auto_start: true
processor:
- bulk_indexing:
queues:
type: bulk_reshuffle
level: shard
bulk_size_in_mb: 1 #in MB
相比前面节点级别的配置,这里主要修改了 level 参数用来监听分片级别类型的磁盘队列,如果索引很多的话本地磁盘队列太多会造成额外的开销,建议仅针对特定要优化吞吐的索引开启该模式。
参数说明 #
| 名称 | 类型 | 说明 |
|---|---|---|
| elasticsearch | string | Elasticsearch 集群实例名称 |
| level | string | 请求的 shuffle 级别,默认为 cluster,也就是集群级别,还可以设置为 cluster、node、index 和 shard 级别 |
| partition_size | int | 在 level 的基础上,会再次基于文档 _id 进行分区,通过此参数可以设置最大的分区大小 |
| fix_null_id | bool | 如果 bulk 索引请求的文档里面没有指定文档 id,是否自动生成一个随机的 UUID,适合日志类型数据,默认 true |
| index_stats_analysis | bool | 是否记录索引名称统计信息到请求日志,默认 true |
| action_stats_analysis | bool | 是否记录批次操作统计信息到请求日志,默认 true |
| doc_buffer_size | int | 设置处理文档的缓冲大小,如果单个索引文档很大,本参数需大于文档大小,默认 262144 即 256 KB |
| shards | array | 字符数组类型,如 "0",设置哪些索引的分片允许被处理,默认所有分片,可以开启只允许特定分片 |
| tag_on_success | array | 将所有 bulk 请求处理完成之后,请求上下文打上指定标记 |